Explaining AML AI models: Making performance metrics clear for Executives and Regulators
In regulated environments like AML, a model without transparency is a model without credibility. Executives won’t trust it. Regulators won’t approve it. Compliance teams are left defending something they can’t fully explain.
Organizations invest hundreds of thousands in Model Governance and yet significant challenges remain, in particular, explainability and transparency.
In larger organizations sophisticated models are in place, but when scrutiny comes, the evidence can be hard to interpret, shrouded in technical terminology and mathematics, making it hard to connect. From Shapley values, feature importance, Kolmogorov–Smirnov (KS) statistics, and area under the curve (PR-AUC) may prove mathematical validity. But they are hard to explain and do not always resonate in the boardroom or with supervisors.
In this blog, we look at how AML leaders can connect technical validation with the clarity that executives and regulators expect.
What executives and regulators really want to know
Executives don’t want equations. Regulators don’t want theory. Both expect clear evidence that a model is reliable and can be trusted.
For executives, the questions are straightforward:
- Why was this case flagged?
- Would the model have caught known risks?
- Is it finding new ones now?
For regulators, the focus sharpens around four pillars:
- Transparency: can individual decisions be explained clearly (e.g. Shapley values)?
- Fairness & Consistency: do broad patterns align with financial and human intuition (e.g. partial dependence plots and bias checks)?
- Validation: does back-testing prove accuracy against historical data?
- Reliability: does forward-testing prove effectiveness in practice?
Rules-based systems could always answer “why,” but at the cost of efficiency and endless false positives. AI fixes inefficiency, but requires deeper organizational capabilities and knowledge to make it explainable.. That’s why AML leaders now need tools that bridge mathematical validity with executive- and regulator-level clarity.
The myth of black box AML models
A model can be watertight mathematically. But if an institution can’t explain what drove an alert, or show how performance holds up under testing, credibility evaporates.
That’s why risk stewards, regulators and executives cannot rely on a defence that alludes to ‘the computer made the decision’ or, in other words, “black box” defense. Executives and regulators want reasoning they can follow, not just impressive metrics.
Models come in many forms.
In AML, “AI model” doesn’t just mean one thing. It could be a decision tree that mimics rule-based logic, a random forest combining multiple decision trees, or a neural network capable of learning complex patterns. These models are all complicated and often, for the uninitiated, can be viewed as a black box. The mathematics may differ, but the regulatory challenge is the same: can you explain why the model made a decision, and can you prove it works?
There are two mathematical tools that give transparency for risk leaders, executives and regulators to understand exactly how the model is operating:
#1. Shapley values = Transparency
Shapley values break down a model’s output into clear drivers. If a customer scores 67 on a risk model, Shapley values show how much each factor contributed: e.g. +65 points for cash deposits above $10k in 72 hours, –18 for account age, –22 for high inflows.
It’s like a school grade: you can see how each subject added to or took away from the total. For investigators, that means they don’t just see a score. They see the geography, counterparties, and transaction patterns that tipped the balance.
#2. Partial dependence plots = Patterns
While Shapley explains a single decision, partial dependence plots show the broader trend. They reveal how one factor, such as monthly inflow, influences scores across the customer base. Some customers might be fine with high inflows, others not. But averaged together, the plot shows the general relationship: more inflow usually means higher risk.
Think of it like sleep and energy. Everyone’s different, but on average, more sleep means more energy. Regulators value these plots because they show models align with intuition and economic logic, not just math.
Together, Shapley values and partial dependence plots replace “black box” outputs with evidence that executives and regulators can defend in plain terms.
Validation and testing: proving effectiveness
Mathematical explainability is only half the story. To truly build confidence, models must be proven against what’s already known and against what’s emerging.
Back-testing = Proven against history
Back-testing takes historical data where outcomes are already known — past alerts, past SARs, confirmed cases — and asks: would the model have caught them?
For compliance, this provides evidence that the model identifies known risks and aligns with regulatory requirements. Done properly, it also demonstrates efficiency gains regulators can verify: better prioritization, fewer false positives, and higher SAR conversion.
With federated learning, back-testing doesn’t stop at the institution’s walls. Peer benchmarking allows banks to show regulators that improvements aren’t just internal claims but are consistent with performance seen across the industry.
Forward-testing = Proven in practice
Forward-testing applies the model to fresh, unseen data and tracks whether it surfaces new risks. Investigators then validate those alerts, showing regulators that the model is adaptive and effective in live environments.
This is where credibility is often won or lost. A forward-test that uncovers emerging typologies missed by legacy systems, and ties them to confirmed outcomes through investigations or law enforcement feedback, provides regulators with proof the model is keeping pace with evolving threats.
Federated learning strengthens this too. By pooling intelligence without exposing raw data, federated models detect emerging patterns faster than isolated ones, giving supervisors assurance that adaptability is not just claimed, but evidenced across institutions.
In short: back-tests show a model would have worked yesterday. Forward tests prove it’s working today. Both are essential for defensibility.
AML that stands up to scrutiny
Regulators want evidence that looks like measurable improvements. They want:
🔵Fewer false positives.
🔵Higher SAR conversion rates.
🔵Faster case resolution.
🔵Backlogs prioritized by risk rather than chronology.
🔵Investigators equipped with scores they can explain and defend in front of an auditor.
Executives want the same thing in plain terms: confidence, clarity, and a narrative they can stand behind when supervisors ask hard questions.
That is the standard AML models now have to meet. And it’s why forward-thinking institutions are turning to approaches that combine explainability, peer benchmarking, continuous learning, and privacy-preserving design.
These methods aren’t beyond reach. Executives and regulators don’t need to be statisticians, but teams do need the capacity to apply these tools and explain them in plain terms. Building that capability is what turns mathematical validity into organizational credibility.
And that’s where we come in.
Consilient’s approach
Consilient’s Core AML/CFT model was developed around these very principles in collaboration with leading banks.
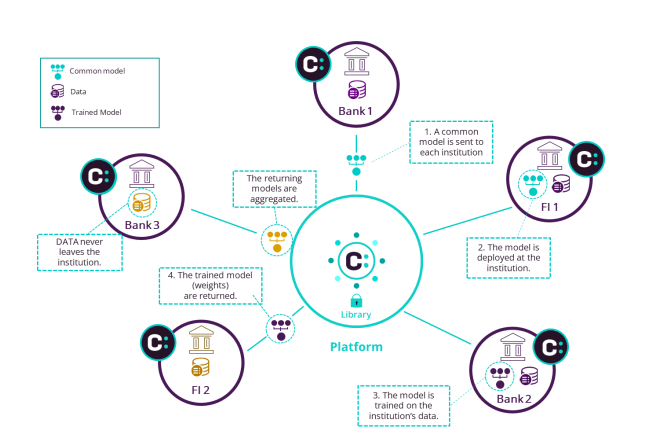
Built to deliver both local precision and global resilience, it provides:
- Transparent risk scoring investigators can defend in plain terms.
- Performance validated against peers through federated benchmarking.
- Models that adapt as financial crime tactics evolve.
- A privacy-preserving architecture where no raw data leaves the institution.
In live testing, this approach has cut false positives by up to 88%, improved detection of previously missed cases, and given regulators defensible evidence through explainability and benchmarking. Keen to learn more? Get in touch today